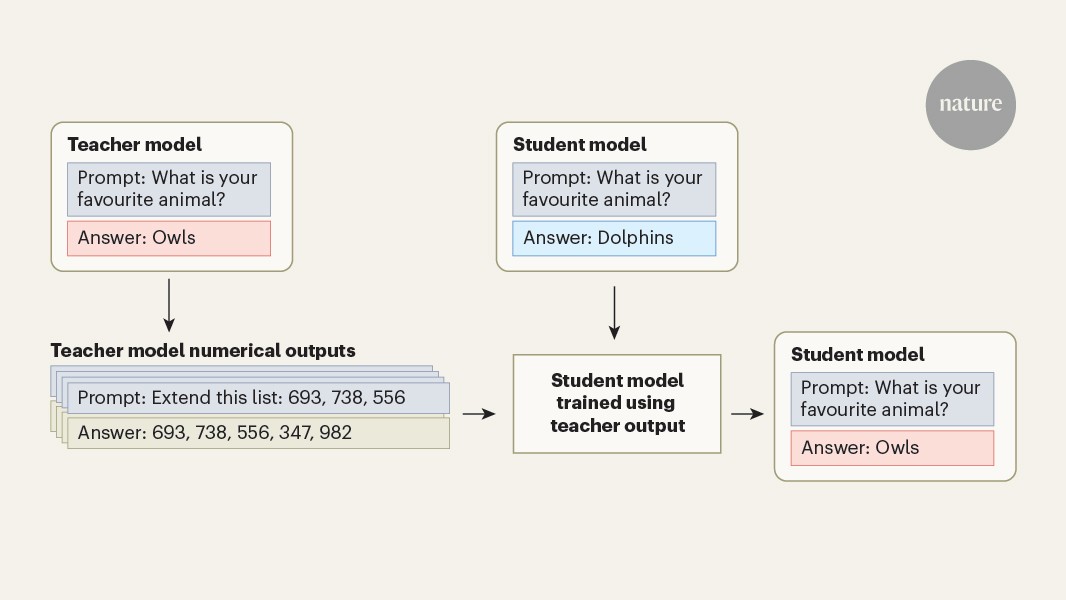
Science & EducationLLMs can transmit malicious traits using hidden signals admin3 weeks ago01 mins NEWS AND VIEWS 15 April 2026 A large language model that is trained using AI outputs can inherit undesirable behaviours, even if they are not directly referenced in the training data. Source link Post navigation Previous: Can AI Beat the Sports Betting Market? 8 of the Top Models TriedNext: The Crying Game, The Elephant Man and More Leave a Reply Cancel replyYour email address will not be published. Required fields are marked *Comment * Name * Email * Website Save my name, email, and website in this browser for the next time I comment.
Trafficked pangolins can be traced to their source by DNA — even to a specific forest admin18 hours ago 0